Figure 1.
| Abstract |
|---|
| Carefull planning of J2EE application configuration is an often neglected aspect of application design. It often suffers further through a myopic focus on the development impacts rather than consideration of other important software lifecycle phases such as build, deployment, environment configuration, and application management. This paper describes an approach to J2EE application configuration that emphasizes application management. |
|
Figure 1. |
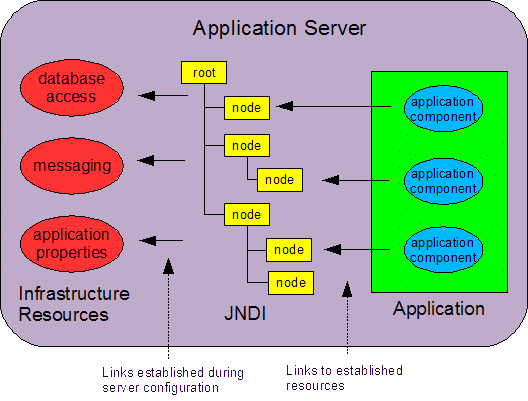
In this sense, the name service entries perform the same function for J2EE applications as the DD statements of mainframe JCL do for COBOL and PL/I programs. The program refers to the resource by a logical name. This name is later resolved to a resource together with parameters that determine how the resource is accessed.
By externalizing its resources, a program becomes more portable
between application environments. When done properly, resource
externalization serves as a "resource catalog" by which operations
staff can properly anticipate an application's resource demands.
This paper will describe the J2EE resource reference mechanism
and how to best put it into practice to maximize application
management. Where it helps to provide detailed examples, WebSphere
Application Server is used.
1 import javax.naming.InitialContext;
2 import javax.naming.Context;
...
3 Context ctx = new InitialContext();
4 DataSource ds = (DataSource)ctx.lookup("jdbc/myDS");
|
Line 3 invokes the service provider's default contructor to acquire an
initial reference to an initial name space context. This is usually the
preferred
way for server-side code that doesn't require any special cache settings
or references to other directories. Line 4 retrieves a reference to the
resource from the location "jdbc/myDS". It's dependent on
the resource existing at this location and being the correct type.
Line 4 in the code above is using a global reference to a name space location. While this may be the most convenient method for the developer, it creates a dependency on the location of the resource in the name space directory. From an application management perspective, the location is hard-coded.
| Definition | In this paper, a hard-coded value refers to a value that cannot be easily inspected or changed by an application administrator. |
In the example above, externalizing the string to a property file that is packaged with the code is still hard-coded from a J2EE application management perspective. Externalizing strings is a great practice. But from an application management perspective (a somewhat different concern than application maintenance), it's an unmanageable value dependent on the external environment.
J2EE application administrators usually manage many applications across many environments. They must wear many hats and cannot affort to become intimately familar with every application they deploy. They should not be expected to dig through deployed archives for property files to change. Moreover, this is a bad practice in a clustered environment (due to server synchronization issues) regardless of how adventurous the administrator might be.
Just as the application is an extension of the server runtime, it's best if the management of the application can be an extension of managing the server runtime. This is not always possible in the more complicated situations. But it should at least be a goal of an application design.
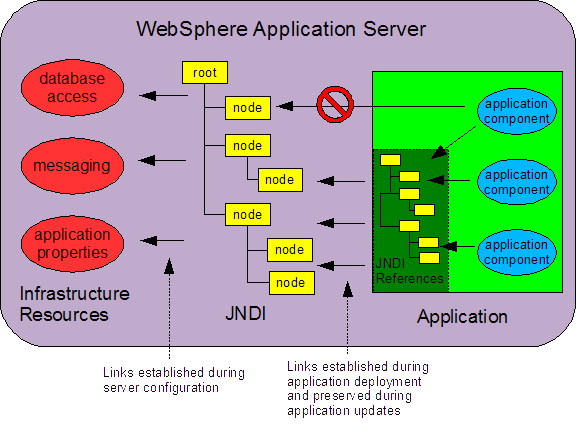
Figure 3 |
Deployment descriptor local references provide developers of
J2EE components with an extra level of indirection by which the
specification of a name space location can be deferred until
deployment time. The figure on the right adds the deployment
descriptor to Figure 1.
The application components refer to local names declared in the
deployment descriptor. These local names are only meaningful
within the deployment descriptor's component. The same names
can be used in other components without conflict.
A special prefix to the name,
java:comp/env, is used to designate the string
as a local reference. The links between the application code and
the deployment descriptors, established during code development,
are represented by the arrows from the blue components to the
dark-green deployment descriptor.
Meanwhile, the administrators of the application infrastructure establish references to all the required resource in the name tree. These resources are colored red in the illustration to the right. The refernces are arrows from JNDI to the red-colored resources. These are established before the application is deployed.
At deployment time, the deployment administration tool will
inspect the EAR file for any references to be resolved. The
resolution of these references is represented by the arrows
from the component's deployment descriptor to the JNDI tree.
Notice that the top arrow is blocked. This represents a
global reference hard-coded to a fixed name space location.
While this is possible, we discourage its use in this paper.
To convert the example of Figure 2 to use local resource references, line 4 would become
4 DataSource ds = (DataSource)ctx.lookup("java:comp/env/jdbc/myDS");
|
The underlined portion is added to designate the reference as local. But in order for this to work, a corresponding entry must be added to the component's deployment descriptor.
|
Developer Inconvenience
Many developers dismiss the name space as a failed attempt to improve on the convenience of property files. Property files are much easier to manage (for a developer), so why bother with JNDI? If I can only make one point throughout this paper, it's that we have to design the configuration aspects of the application with the entire lifecycle in mind. The largest obstacle to this realization is that the parties who most benefit from better application management, such as the build-release staff and the infrastructure staff, are the least educated about the configuration mechanisms gauranteed by conformance to the J2EE specification. At best, a few developers might understand, but they are the least motivated to put them into place. The problem is further exacerbated from an industry perspective. An application server vendor does not sell to the build or the release or the infrastructure groups. Who's ever heard of a vendor calling up the release group of an enterprise to espouse the application management benefits of the J2EE platform? It aways begins with the development group. They make the purchasing decisions; and so it's their perspective that's accomodated by vendor product managers and available training rather than a balanced perspective across all the application roles. With all these forces working against sound application configuration, it's no wonder that it is still such a challenge and will remain so for years to come. |
1 <resource-ref> 2 <res-ref-name>jdbc/myDS</res-ref-name> 3 <res-type>javax.sql.DataSource</res-type> 4 <res-auth>Application</res-auth> 5 <res-sharing-scope>Shareable</res-sharing-scope> 6 </resource-ref> |
The jdbc/myDS of the string in line 4 of the code must
match the value of the <res-ref-name> tag in line
2 of the deployment descriptor. Local references have the following
benefits.
This is, of course, an inconvenience for the developer. For each such resource referenced, the developer must add a corresponding entry into the deployment descriptor. As the code sample above demonstrates, this isn't a whole lot. But it does make the deployment descriptor (even more of) a source of merge conflicts in source control, since everyone working on a particular J2EE component uses the same deployment descriptor.
But the most common cause of neglecting local resource referenes are ignorance and apathy. Application management simply isn't stressed in J2EE education venues: whether they be classes, books, mentoring or articles on the web. The apathy factor is more complicated than simply developers who don't care. Rather, many J2EE developers were trained to write stand-alone applications. Writing an application to share resources with other applications and lend itself to management in a standard way, was never a success criterion. The whole notion of application management means something different to a developer - who has a workstation environment configured for informal debugging of a few applications, rather than formal management of many applications.
By accessing files and network connections through application server resource references, the resource is accessed on behalf of the server runtime, not the application itself. The resources made available to the application are only those explicitly configured and scoped for the application by the application server administrator.
Creating resource references for database and messaging resources is a rather standard practice in most organizations. Leaving these kinds of configuration for the operations-staff to handle ensures that EAR files are portable across environments. Any time a separate build must occur simply to promote an application from one environment to another, that's a sign that internal property files were used instead of name space entries. In most cases these property files are not necessary. They are just a habit that some developers acquire from their experience with stand-alone application development. Not all property file usage is bad. The following sections present criteria to help determine when they are appropriate.
| Definition | If changing an application configuration property warrants re-testing of the application, the property is an internal property. Otherwise it is an external property. |
Several types of external references and their trade-offs are
discussed below.

The URL resource is an often
neglected mechanism for managing
access to either the file system or network sockets. Rather than
accessing either of these types of resources directly, an application
should declare such a dependency through a
local reference in the deployment descriptor
and obtain the java.net.URL from JNDI.
An example URL configuration is captured in the figure on the right.
The J2EE specifications recommends that JNDI names of this sort
begin with "url."
The Specification field is where the URL is listed. For a
file, this will begin with "file:///". For a Windows
file system, this will be followed by a drive letter and a colon
like in the example. For a Unix file system, "file:///"
specifies the root directory.
As explained in the
section on dynamics, if the URL specifies a
file, changes to the underying file will be realized immediately.
But changes to the location of the file will not be realized by
the reference until the application is restarted.
|
Scope Subtlies
The WebSphere Application Server name space is tree-structured with a root cell entry and child node entries. Each of the nodes in turn has child entries for each of its servers. Name space entries may be placed at any of these levels. But in most cases, entries are bound to the server level. Resource references, such as data sources, messaging entries, and URLs, are always bound to the server level to the name space. When the scope for a resource reference is changed to a node or cell scope, it's not causing the entry to be bound higher up in the name space hierarchy. Rather, it's causing the reference to be bound at multiple server locations that fall under the scope choice. So if a data source is assigned to "node scope", it is bound to the name space server scope of every server under that node. It does not actually get bound to the node-level entry of the name space tree. This practice makes resources much easier to locate. Applications do not have to search the name space scopes. They simply start with their bootstrap location (which for the default constructor of line 3 in Figure 2, is the server scope). Name space bindings are different. When a node scope is specified for a name space binding, it is actually bound to the node scope in the name tree; not to the server scope for each server under the specified node. If local references are used, the proper scope location can be resolved at deployment time. |
As shown below, the Name Space Bindings section of the Administration Console is located under Environment → Naming → Name Space Bindings. Click this link to display a list of name space bindings.
The screen-shot shown below is a sample of such a list. In this case, it contains a sample entry called DebugMode. The following instructions demonstrate how to create such an entry. It's important to choose the scope of the entry carefully.
The impact of the scope choice is subtly different between name space bindings and resources. (See the side-bar for more information.) Server-scope is the easiest to work with. Click the New button to begin configuration of a string name space binding. Select the String option and click Next.
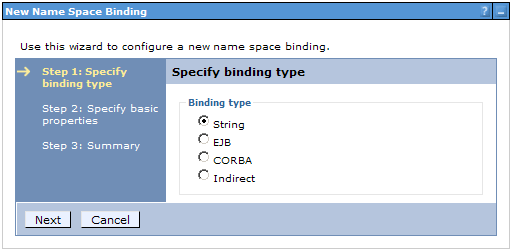
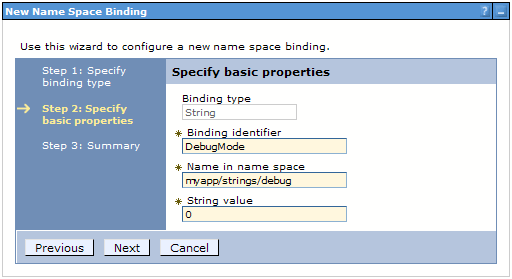
The Binding Identifier can be any string that helps you remember
the purpose of the binding. The Name in name space should be
considered as any other JNDI name. But unlike other resources, it's
unlikely to be shared by other applications. So you might want to
prefix the name with the application name. That way, each application
can have its own debug mode. Adding "strings" within
the name simply provides an indication of the type. It's analogous
to prepending "jdbc" or "url" to resource
entries.
The last page is simply a summary page. This completes the configuration.
One drawback of string name space bindings is that the WAS administration console does not optimize the management of a large number of them. For example, you can list all available bindings as shown in Figure 6, but you can't see their individual values unless you click on their entries. This can make it difficult to inspect a large number of them quickly.
Another drawback is that large numbers of string name space bindings become a burden for configuring new envirenments. It's easy to recommend scripting (and it does work). But we all know what a pleasure that is.
Once again, it's important to use URL
resources rather than direct file access through the
java.io.File mechanism for the
reasons stated above. This compromise still
requires that the application server administrator has access to the
file system. But at least the specific location is abtracted away
from the application. Meanwhile, the fact that it requires such a
file is cataloged in the component's deployment descriptor, assuming
local references are used.
<env-entry> element provides for a
component-specific property to be bound as a local resource
into the name space. It is retrieved from JNDI in the same
manner as other local resource entries, throught the
java:comp/env context of the local environment.
These entries are intended to be viewable and editable during
the application assembly and deployment phases for a component.
They are not editable after deployment through the
standard administration tools. This is in contrast to the
string name space bindings which should be
referenced from the deployment descriptor (using the
<resource-env-ref> elements), but
configured independently by the application server
administrator.
Another example of an internal property is the servlet
initialization parameter. It is added to a web application
deployment descriptor through the <init-param>
tag. Servlets can access an initialization parameter
through the getInitParameter method of the
ServletContext object. It's value is set in
the deployment descriptor and can be edited during the
application assembly phase. Such values are not intended
to be modified once deployed.
Name space resources are configured and bound into the name space at application server start-up. So name space caching aside, these entries are not even updated in the name space, let alone the cache, until the server is restarted. Remember that resource references are bound once for each server falling under the specified scope. So if a data source is bound at node scope, each application on the node must be restarted to realize changes in the data source configuration.
Name space binding changes are applied to the name space immediately. However, the default behavior for JNDI is to leverage a name space cache. There is no event listener mechanism to refresh the cache in the event of a change. So with the default behavior, the server must still be restarted to realize the change in value.
The default behavior can be changed by supplying a hash table to the constructor of line 3 in Figure 2 that disables the cache. This has the potential to degrade performance considerably. If this option is implemented, it should be restricted to only the name space entries that must be read dynamically, allowing others to utilize the cache.
Propery files read from URL resources always get the latest contents. So they are dynamic in the sense that the property changes can be updated and subsequent reads will acquire their latest values. However, the URL resource reference, as oppose to the resource itself, will not be updated until the next application server restart. So while changing the properties in the external property file is dynamic, moving the property file is not.
